我这一年的技术学习概况
2016年上半年5月之前,准备中级软考,主考软件设计师,最后没有考过。考证的主要出发点是恶补下计算机基础,能过最好过不了也可以接受。开始写技术日志是从2016年的7月,那段时间在学习java代码,曾尝试阅读公司商城的源代码,代码大而全,确实切入困难,尝试过了解spring的架构之类的,最后还是没有达到看源码的水平。用java写了个自动登录系统投票的小软件给未...
本文转自:http://blog.csdn.net/wwwqjpcom/article/details/51232302
本文中的样例均使用SoapUI ,关于SoapUI+Webdriver 的配置,请看上一篇:
http://blog.csdn.net/wwwqjpcom/article/details/51174664
我弄这个的本意是为了在SoapUI中更好地编写自动化用例,因为我的业务流程有的很长,有7-8个页面。
我想把代码不集中在一个Groovy 脚本里,想在第二个脚本中继续使用第一个脚本中打开的浏览器。这样便于
维护和定位问题。
也还有一种情况是我打开了浏览器,,操作了系统到某一个界面后,我写了这个页面的测试脚本,使用已
打开的浏览器我立刻就可以单独对这个页面进行测试,测试我写的代码是否OK 。不通过就人工操作复位页面,
修改代码后再次测试,不用每次测试代码是否可行都从头打卡浏览器,登录系统,重新操作了。可以实现分步
单页面调试自动化脚本。
首先,来简单看一下Selenium Webdriver如何工作的。
(1)Selenium代码调用API实际上根据 The WebDriver Wire Protocol 发送不同的Http Request 到 WebdriverServer。
IE 是 IEDriverServer.exe
Chrome是ChromerDriver,下载地址: https://sites.google.com/a/chromium.org/chromedriver/downloads
Firefox是以插件的形式,直接在selenium-server-standalone-XXX.jar里了:
webdriver.xpi (selenium-server-standalone-2.48.2.jar中/org/openqa/selenium/firefox/目录下)
new FirefoxDriver()时,启动Firefox浏览器时,带此插件一起启动,然后插件会默认监听7055端口,7055被占用就使用下一个端口。如下图所示。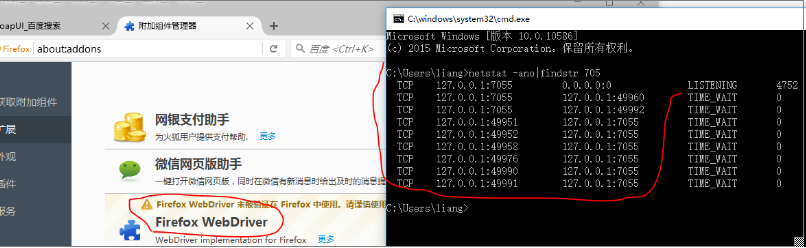
同一台机器上可以同时启动多个FirefoxDriver实例,每个实例占用不同的端口号。
1 | The WebDriver Wire Protocol 协议的具体内容请看:https://code.google.com/p/selenium/wiki/JsonWireProtocol#Introduction。 这个协议现在正在被W3C标准化,W3C Webdriver,两者基本一样。 |
(2)WebdriverServer接收到Http Request之后,根据不同的命令在操作系统层面去触发浏览器的”native事件“,
模拟操作浏览器。WebdriverServer将操作结果Http Response返回给代码调用的客户端。
为了更清晰直观地看到这个是如何运转的,我们来在使用OWASP ZAP做代理,截获Http Request和Response来看一下。
首先安装OWASP ZAP或其他有代理功能的工具,设置SoapUI Proxy,如ZAP默认使用8080端口,则SoapUI配置如下: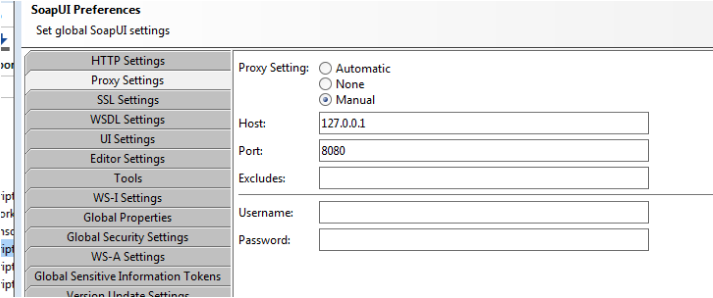
配置完SoapUI端口后,好像需要重启SoapUI,然后在SoapUI 的自动化测试代码中,代理才能正常工作。
重新跑前一节FirefoxDriver的代码,查看截获的请求和响应。如下图所示: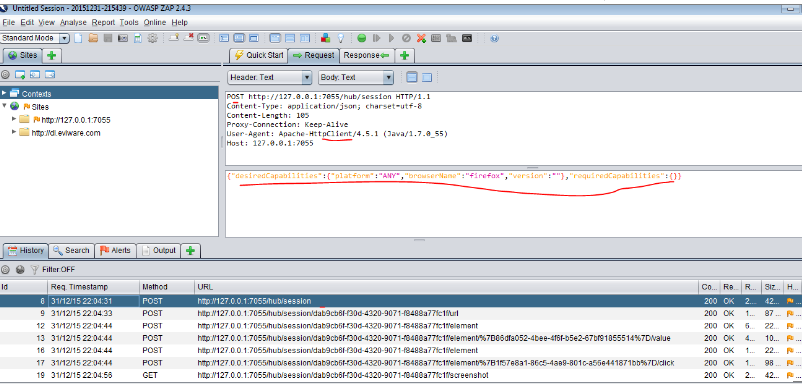
本文转自:blog.csdn.net/zzzmmmkkk/article/details/10034213
布局和JavaScript
浏览器自动化工具基本上由三部分构成:
·与DOM交互的方法
·执行Javascript的机制
·一些模拟用户输入的办法
本节重点介绍第一部分:提供与DOM交互的机制。浏览器的办法是通过Javascript,所以看起来与DOM交互的理想语言也是它。虽然这种选择似乎显而易见,但是在考虑Javascript时需要平衡一些有趣的挑战和需求。
像多数大型项目一样,Selenium使用了分层的库结构。底层是Google的Closure库,提供原语和模块化机制来协助源文件保持精简。在此之上,有一个实用工具库,提供的函数包括简单的任务,如获取某个属性值、判断某个元素是否对用户可见,还包括更加复杂的操作,如通过合成事件模拟用户点击。在项目中,这些被视为提供最小单元的浏览器自动化,因此称之为浏览器自动化原子(Browser Automation Atom)。最后,还有适配层来组合这些原子单元以满足WebDriver和Core的API协议。
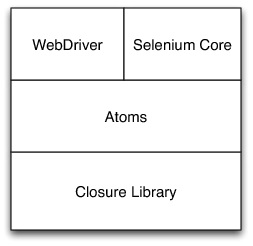
图 3:Selenium Javascript库的层次结构
选择Closure库基于几种原因。主要理由是Closure编译器理解库使用的模块化技术。Closure编译器的目标是输出Javascript。“编译”可以简单到按照依赖顺序查找输入文件、串联并漂亮的打印出来,也可能复杂到进行精细的改动和删除死代码。另一种不可否认的优势是团队中采用Javascript编程的几位成员对Closure库非常熟悉。
当需要与DOM交互时,“原子”库的代码会被用于项目中的各个角落。对于RC和那些大部分由Javascript编写而成的driver来说,这些库被直接使用,通常编译为单个巨大的脚本。对于采用Java编写的driver,来自WebDriver适配层的各个函数在编译的时候会启用完整优化,生成的Javascript在JAR中作为资源包含进来。对于采用C语言编写的driver,如iPhone IE驱动,不仅各个函数被通过完整优化来编译,而且生成的输出文件被转换成定义在头文件中的常量,通过driver的正常Javascript执行机制来执行。虽然这看起来有些奇怪,但是这种做法使Javascript放在底层驱动中,无须在各处暴露原始的代码。
因为原子库应用广泛,所以在不同浏览器之间确保一致的行为是可行的,因为库采用Javascript编写,而且无需提升权限来执行开发周期,所以方便、快捷。Closure库可以动态加载依赖,因此Selenium开发人员只需编写测试并在浏览器中加载,修改代码并在需要时点击刷新按钮。一旦测试在浏览器中通过,很容易在另一个浏览器中加载并确保通过。因为Closure库在抽象屏蔽浏览器之间的差异方面做得很好,这就足够在持续构建中在每一种支持的浏览器中运行测试集以衡量是否通过。
最初Core和WebDriver存在许多相同的代码——通过略微不同的方式执行相同的功能。当我们开始关注原子库时,这些代码被重新梳理,我们努力找出最合适的功能。毕竟,两个项目都被广泛应用,它们的代码非常健壮,因此把一切都丢掉从零开始不仅浪费而且愚蠢。通过对每个原子库的分析,我们找出了可以使用的部分。例如,Firefox driver的getAttribute方法从大约50行缩减到几行,包括空白行在内:
FirefoxDriver.prototype.getElementAttribute =function(respond, parameters) {var element = Utils.getElementAt(parameters.id, respond.session.getDocument());var attributeName = parameters.name;respond.value = webdriver.element.getAttribute(element, attributeName);respond.send();};
倒数第二行中,respond.value的赋值调用了原子级的WebDriver库。
原子库是本项目若干架构思想的实际演示。当然,它们满足了API的实现应该倾向于Javascript的需求。更出色的是,用一个库在代码库中分享,以前一个缺陷需要在多种实现中验证和修复,现在只需在一个地方修改即可,这种做法降低了变化的成本,同时提高了稳定性和有效性。原子库也使项目的“巴士”因素更优化。因为通常的Javascript单元测试可以用于验证缺陷是否修复,所以参与到开源项目中的障碍要比之前需要了解每一个driver如何实现的时候更低。
使用原子库还有另外一个好处。模拟现有RC实现但由WebDriver支持的分层对团队尝试以可控的方式迁移到更新的WebDriver API是一种重要的工具。因为Selenium Core是原子化的,所以单独编译每一个函数是可行的,使得编写这种模拟层易于实现而且更准确。
当然,这种做法也存在缺点。最重要的是,把Javascript编译成C常量是一种非常奇怪的事情,它总是阻碍那些想参与C语言编程的项目贡献者。而且很少有开发人员能够了解所有浏览器并致力于每一种浏览器上运行所有测试——很可能有人会不小心在某处引入回归问题,我们需要花时间找到问题,如果持续构建很多的话则更需精力。
本文引至:http://blog.csdn.net/zzzmmmkkk/article/details/9274781
当你看到这篇文章时一定会诧异,2.0都广泛使用了,为何还要了解1.0的内容呢?1.0的确已经慢慢的成为历史,那我们就先通过历史来认识一下selenium的发展吧。
Jason Huggins在2004年发起了Selenium项目,当时他在ThoughtWorks公司开发内部的时间和费用(Time and Expenses)系统,该应用使用了大量的JavaScript。虽然IE在当时是主流浏览器,但是ThoughtWorks还使用一些其他浏览器(特别是Mozilla系列),当员工在自己的浏览器中无法正常运行T&E系统时就会提交bug。当时的开源工具要么关注单一浏览器(通常是IE),要么是模拟浏览器(如HttpUnit),而购买商业工具授权的成本会耗尽这个小型内部项目的有限预算,所以它们都不太可行。
幸运的是,所有被测试的浏览器都支持Javascript。Jason和他所在的团队有理由采用Javascript编写一种测试工具来验证应用的行为。他们受到FIT(Framework for Integrated Test)的启发,使用基于表格的语法替代了原始的Javascript,这种做法支持那些编程经验有限的人在HTML文件中使用关键字驱动的方式来编写测试。该工具,最初称为“Selenium”,后来称为“Selenium Core”,在2004年基于Apache 2授权发布。
Selenium的表格格式类似于FIT的ActionFixture。表格的每一行分为三列。第一列给出了要执行的命令名称,第二列通常包含元素标记符,第三列包含一个可选值。例如,如下格式表示了如何在名称为“q”的元素中输入字符串“Selenium”:
type name=q Selenium
因为Selenium过去使用纯JavaScript编写,它的最初设计要求开发人员把准备测试的应用和Selenium Core、测试脚本部署到同一台服务器上以避免触犯浏览器的安全规则和JavaScript沙箱策略。在实际开发中,这种要求并不总是可行。更糟的是,虽然开发人员的IDE能够帮助他们快速处理代码和浏览庞大的代码库,但是没有针对HTML的相关工具。人们很快意识到维护一个中等规模的测试集是笨拙而痛苦的过程。
为了解决这个问题和其他问题,他们编写了HTTP代理,这样所有的HTTP请求都会被Selenium截获。使用代理可以绕过“同源”规则(浏览器不支持Javascript调用任何当前页面所在服务器以外的其他任何东西)的许多限制,从而缓解了首要弱点。这种设计使得采用多种语言编写Selenium成为可能:它们只需把HTTP请求发送到特定URL。连接方法基于Selenium Core的表格语法严格建模,称之为“Selenese”。因为语言绑定在远程控制浏览器,所以该工具称为“Selenium Remote Control”或者“Selenium RC”。
就在Selenium处于开发阶段的同时,另一款浏览
器自动化框架WebDriver也正在ThoughtWorks公司的酝酿之中。Selenium2.0之webdriver的介绍请期待下一篇文章。
上面介绍中其实也提到了1.0的概况,下图就是它的流程。
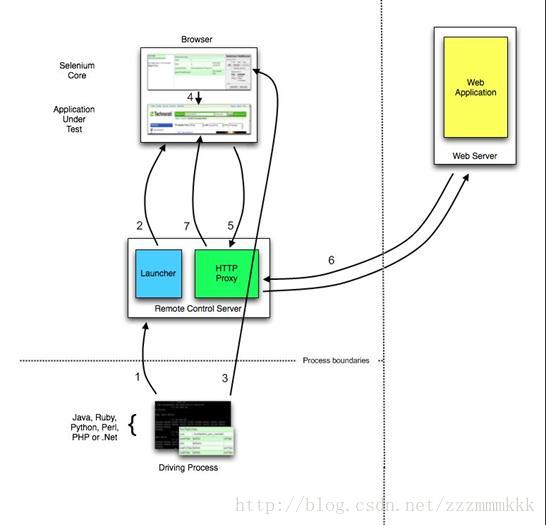
测试用例通过Http请求建立与 selenium-RC server 的连接
Selenium RC Server 驱动一个浏览器,把Selenium Core加载入浏览器页面当中,并把浏览器的代理设置为Selenium Server的Http Proxy
执行用例向Selenium Server发送Http请求,Selenium Server对请求进行解析,然后通过Http Proxy发送JS命令通知Selenium Core执行操作浏览器的动作并注入 JS 代码
4.Selenium Core执行接受到的指令并操作
当浏览器收到新的请求时,发送http请求
Selenium Server接收到浏览器发送的Http请求后,自己重组Http请求,获取对应的页面
Selenium Server中的Http Proxy把接受到的页面返回给浏览器。
1、selenium.common.exceptions.ElementNotVisibleException: Message: element not visible
2、selenium.common.exceptions.InvalidElementStateException: Message: invalid element state: Element is not currently interactable and may not be manipulated
出现以上两种异常的原理:
1、元素还没加载出来就操作,通常是alert框,解决办法time.sleep(1),时间自己调试。
2、元素你看得到,但是代码要操作的元素是跟随鼠标变更样式的,或者其他条件实时变更的,导致代码不能“看见”。这种情况就需要通过js操作dom元素来适应场景。
我测试页面有一个input,在鼠标不操作是时候样式如下:
1 | <input id="batch_quto" value="0" data-role="numerictextbox" role="spinbutton" style="display: none;" class="k-input" type="text" aria-valuemin="0" aria-valuenow="0" aria-disabled="false" aria-readonly="false"> |
当鼠标点击输入框,样式变为:
1 | <input id="batch_quto" value="0" data-role="numerictextbox" role="spinbutton" style="display: inline-block;" class="k-input" type="text" aria-valuemin="0" aria-valuenow="0" aria-disabled="false" aria-readonly="false"> |
二者的区别:
1 | style="display: none;" |
display 属性设置元素如何显示。所以无论是通过xpath、id来定位元素都无法用代码输入文本到input。
解决方法,使用splinter的js执行方法操作该input 的style属性,而要在你操作的若干个div嵌套中发现你操作的元素才是真正的难点:
1 | # 以下4行代码耗费我3天的时间实验验证得出 |