Selenium 2.0的由来及设计架构
条评论本文转自:blog.csdn.net/zzzmmmkkk/article/details/10034213
布局和JavaScript
浏览器自动化工具基本上由三部分构成:
·与DOM交互的方法
·执行Javascript的机制
·一些模拟用户输入的办法
本节重点介绍第一部分:提供与DOM交互的机制。浏览器的办法是通过Javascript,所以看起来与DOM交互的理想语言也是它。虽然这种选择似乎显而易见,但是在考虑Javascript时需要平衡一些有趣的挑战和需求。
像多数大型项目一样,Selenium使用了分层的库结构。底层是Google的Closure库,提供原语和模块化机制来协助源文件保持精简。在此之上,有一个实用工具库,提供的函数包括简单的任务,如获取某个属性值、判断某个元素是否对用户可见,还包括更加复杂的操作,如通过合成事件模拟用户点击。在项目中,这些被视为提供最小单元的浏览器自动化,因此称之为浏览器自动化原子(Browser Automation Atom)。最后,还有适配层来组合这些原子单元以满足WebDriver和Core的API协议。
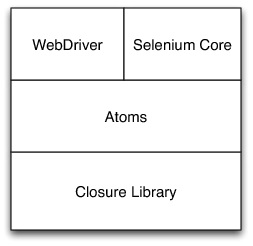
图 3:Selenium Javascript库的层次结构
选择Closure库基于几种原因。主要理由是Closure编译器理解库使用的模块化技术。Closure编译器的目标是输出Javascript。“编译”可以简单到按照依赖顺序查找输入文件、串联并漂亮的打印出来,也可能复杂到进行精细的改动和删除死代码。另一种不可否认的优势是团队中采用Javascript编程的几位成员对Closure库非常熟悉。
当需要与DOM交互时,“原子”库的代码会被用于项目中的各个角落。对于RC和那些大部分由Javascript编写而成的driver来说,这些库被直接使用,通常编译为单个巨大的脚本。对于采用Java编写的driver,来自WebDriver适配层的各个函数在编译的时候会启用完整优化,生成的Javascript在JAR中作为资源包含进来。对于采用C语言编写的driver,如iPhone IE驱动,不仅各个函数被通过完整优化来编译,而且生成的输出文件被转换成定义在头文件中的常量,通过driver的正常Javascript执行机制来执行。虽然这看起来有些奇怪,但是这种做法使Javascript放在底层驱动中,无须在各处暴露原始的代码。
因为原子库应用广泛,所以在不同浏览器之间确保一致的行为是可行的,因为库采用Javascript编写,而且无需提升权限来执行开发周期,所以方便、快捷。Closure库可以动态加载依赖,因此Selenium开发人员只需编写测试并在浏览器中加载,修改代码并在需要时点击刷新按钮。一旦测试在浏览器中通过,很容易在另一个浏览器中加载并确保通过。因为Closure库在抽象屏蔽浏览器之间的差异方面做得很好,这就足够在持续构建中在每一种支持的浏览器中运行测试集以衡量是否通过。
最初Core和WebDriver存在许多相同的代码——通过略微不同的方式执行相同的功能。当我们开始关注原子库时,这些代码被重新梳理,我们努力找出最合适的功能。毕竟,两个项目都被广泛应用,它们的代码非常健壮,因此把一切都丢掉从零开始不仅浪费而且愚蠢。通过对每个原子库的分析,我们找出了可以使用的部分。例如,Firefox driver的getAttribute方法从大约50行缩减到几行,包括空白行在内:
FirefoxDriver.prototype.getElementAttribute =function(respond, parameters) {var element = Utils.getElementAt(parameters.id, respond.session.getDocument());var attributeName = parameters.name;respond.value = webdriver.element.getAttribute(element, attributeName);respond.send();};
倒数第二行中,respond.value的赋值调用了原子级的WebDriver库。
原子库是本项目若干架构思想的实际演示。当然,它们满足了API的实现应该倾向于Javascript的需求。更出色的是,用一个库在代码库中分享,以前一个缺陷需要在多种实现中验证和修复,现在只需在一个地方修改即可,这种做法降低了变化的成本,同时提高了稳定性和有效性。原子库也使项目的“巴士”因素更优化。因为通常的Javascript单元测试可以用于验证缺陷是否修复,所以参与到开源项目中的障碍要比之前需要了解每一个driver如何实现的时候更低。
使用原子库还有另外一个好处。模拟现有RC实现但由WebDriver支持的分层对团队尝试以可控的方式迁移到更新的WebDriver API是一种重要的工具。因为Selenium Core是原子化的,所以单独编译每一个函数是可行的,使得编写这种模拟层易于实现而且更准确。
当然,这种做法也存在缺点。最重要的是,把Javascript编译成C常量是一种非常奇怪的事情,它总是阻碍那些想参与C语言编程的项目贡献者。而且很少有开发人员能够了解所有浏览器并致力于每一种浏览器上运行所有测试——很可能有人会不小心在某处引入回归问题,我们需要花时间找到问题,如果持续构建很多的话则更需精力。
因为原子库规范了浏览器之间的返回值,所以可能存在意想不到的返回值。例如,考虑如下HTML:
checked属性值依赖于使用的浏览器。原子库规范了该值和HTML 5标准中定义的其他Boolean属性为“true”或者“false”。当该原子量被引入代码库后,我们发现有许多地方大家都做了依赖于浏览器的假设(觉得返回值应该是什么样的)。虽然这些值现在都一致了,但是我们花了很长时间来向社区解释发生了哪些变化以及这样做的原因。
特别介绍下Remote Driver和Firefox Driver
起初remote driver是一种很不错的RPC实现机制,自从它演变成一种主要的实现机制后,我们通过能使用代码实现的语言绑定这样的通用接口来降低维护Webdriver的成本。尽管我们从语言绑定移除了大量的逻辑到driver中,如果每一种driver需要通过唯一的协议来交互,我们仍然有大量重复的代码在语言绑定中。
当我们需要与没有运行的浏览器实例交互时就使用Remote driver协议,设计这个协议做了诸多方面的考虑,大多数都是技术性的,但是作为开源软件来说这些也都成了社会性方面要考虑了。
任何RPC机制都分为两部分:传输和加密。我们知道Remote driver协议无论完成到什么程度,要想用作客户端在编程语言上仍然需要支持这两点,设计的第一次迭代就是作为Firefox driver的一部分来开发的。
Mozilla常被它的开发人员作为一个支持多平台的应用程序,所以Firefox也如此。为了开发更便捷,Mozilla开发了一种框架,在微软的COM基础上允许构建多组件,捆绑在一起称为XPCOM(跨平台的COM)。XPCOM接口定义为使用接口定义语言,支持C, javescript及其他多种语言。因为XPCOM用于构建Firefox,并且具备Javascript绑定,那么在开发Firefox扩展上使用XPCOM对象成为了可能。
普通的win32 COM允许远程访问接口,同样我们也计划让XPCOM实现,Darin Fisher添加了一个XPCOM ServerSocket完成。尽管D-XPCOM计划没有结果,但是退化的基础框架仍然存在。我们利用这个创建了一个基本的服务器,包含了自定义的Firefox的扩展,实现了能控制firefox的所有逻辑。最初使用的协议是基于文本和面向行的,所有的字符串编码为UTF-2,每个请求及响应都是以一个数字开始,标示有请求或回复被发送前计算出有多少新行。最重要的是,这个方案很容易使用javascript实现因为SeaMonkey(此时firefox的javascript引擎)内部把Javascript字符串存储为16 bit无符号整数。
尽管通过原始套接字协议把玩自定义编码是一个有趣的打发时间的方式,但它有几个缺点。当时还没有供自定义协议广泛使用的库,所以我们想需要从零开始实现并支持每一种语言,这要求实现更多的代码,使得让慷慨的开源贡献者参与开发新的语言绑定不太可能。此外,当我们只发送基于文本的数据时,虽然面向行的协议是很好的,但是当我们想发送图像(如截图)时会带来一些问题。
它非常明显非常快的说明了这种原始的RPC机制是不切实际的。幸运的是,有一个著名的传输协议,在几乎每种语言上被广泛的采纳和支持,这将使我们能做任何想做的,这就是HTTP协议。
当我们决定使用HTTP进行传输时,下一步选择就是是否要使用一个单一的端点(SOAP)或多个端点(REST风格)Selenese的协议,用于一个单一的端点,并在查询字符串命令和参数中编码。虽然这种方法效果很好,但是“感觉”不对。我们的愿景是能够连接到浏览器远程webdriver实例查看服务器状态,我们最后选择的方法称之为“REST-ish”:多个端点的URL使用http,以帮助提供功能,但打破了需要一个真正的RESTful系统的约束,尤其是状态的位置和周围缓存能力,主要是因为应用程序的状态,只有一个有意义的位置存在。
虽然HTTP可以很容易的支持多种方式基于内容类型协商的数据编码方式,我们决定我们需要一个规范的形式,实现让所有远程webdriver协议可以协同工作。很明显有一大把的选择:HTML,XML或者JSON。我们很快排除了XML:虽然它是一个完全合理的数据格式,并且有很多类库,几乎每一种语言都支持。即便在开源社区人们多喜欢它,但是我们不喜欢使用它。此外,尽管返回的数据将使用一个共同的“格式”,但它完全有可能很容易地使其他字段变成added3(不解为何意思?)。虽然这些扩展可以参照使用XML的命名空间,但将开始引入更多复杂的客户端代码:我竭力所避免的东西。XML被丢弃作为一个选项。HTML真的不是一个不错的选择,因为我们需要能够定义我们自己的数据格式,虽然嵌入式微格式可能已经定义被使用,猛地被锤子砸了一下一样。
最终的可能性是Javascript对象表示法(JSON)。浏览器可以将字符串转换成对象,直接调用eval函数,或者在更多较新的浏览器上结合原始特性安全无副作用的从一个字符串改造成一个Javascript对象或把Jaascript对象改造成字符串。从现实角度看,JSON是一种流行的数据格式,拥有丰富的类库可支持几乎每种语言,所有酷小伙儿都喜欢它,一个很容易的选择。
远程Webdriver协议的第二次迭代因此使用了HTTP传输机制和UTF-8编码的JSON作为默认的编码,使客户端可以很容易的使用各种有限支持Unicode的语言,因为UTF-8向后兼容ASCII。发送给服务器的命令使用URL以确定哪个命令被发送,并编码在一个数组中的命令的参数。
Webdriver远程协议有两个错误处理层次,一个无效的请求和一个失败的命令。无效的请求的例子是请求一个服务器并不存在的资源,或者可能是资源不理解,(例如发送一个DELETE命令给用于处理当前页面的URL的资源)。这种情况下,一个正常的HTTP响应是4XX。对于失败的命令,错误码设置为500(服务器端错误),并且返回的数据包含更详细的错误分解。
当包含数据的响应从服务器发出后,它是一个JSON对象的格式:
Key描述
Sessionid服务器使用的决定何处路由特定会话命令的不透明处理
状态值 一个概括命令结果数字状态码,非零值代表命令失败响应的JSON值
例如:
FirefoxDriver.prototype.getElementAttribute =function(respond, parameters) {var element = Utils.getElementAt(parameters.id, respond.session.getDocument());var attributeName = parameters.name;respond.value = webdriver.element.getAttribute(element, attributeName);respond.send();};
因为可见,我们会在响应中编码状态码,使用非零值表示发生了糟糕的事故。首先在IE driver上使用了状态码,而且被用于了线协议。因为所有的错误码在不同的driver中一致的,在不同的driver中可以使用特殊的语言完成共享错误处理的代码,使客户端更容易实现。
远程webdriver服务简单讲是一个Java servlet,扮演多重角色,路由收到的所有的命令给对应的Webdriver实例。诸如此类的事情,一个大二的学生都能完成。Firefox driver也完成了远程Webdriver协议,它的架构更加有趣,所以让我们跟踪一个从语言绑定的会话到后端一直到返回给用户的请求。
假设我们使用JAVA,element就是WebElement的一个实例,这样开始:
element.getAttribute(“row”);
在内部,元素有一个透明的ID,服务器用于识别是哪一个元素。为了便于讨论,我们假设这个ID有一个值some_opaque_id,被加密成JAVA命令对象,使用MAP映射到一个参数ID和name,表示用于要查询的属性名的元素ID和name。
快速看一下正确的URL是:
/session/:sessionId/element/:id/attribute/:name
以冒号开始的URL的任何部分假定是一个需要被替换的变量,我们已经获得ID和name,当一个服务器可以同时处理多个会话(Firefox driver不能)时,那么sessionId是另一种用于路由功能的不透明的句柄,这个URL因此像这样扩展:
http://localhost:7055/hub/session/XXX/element/some_opaque_id/attribute/row
顺便说一句,webdriver的远程线协议最初是在与URL模板草案提出时同时开发的,我们以明确URL及URL模板的方案允许在一个URL里进行变量扩展(派生)。遗憾的是,虽然URL模板同时提出,我们只意识到他们相对晚了一天,因此他们不会被用作设计线协议。
因为我们正执行的方法是idempotent4,正确的HTTP方法是使用get,我们委托一个能处理HTTP(Apache的HTTP客户端)来调用服务器的Java库。
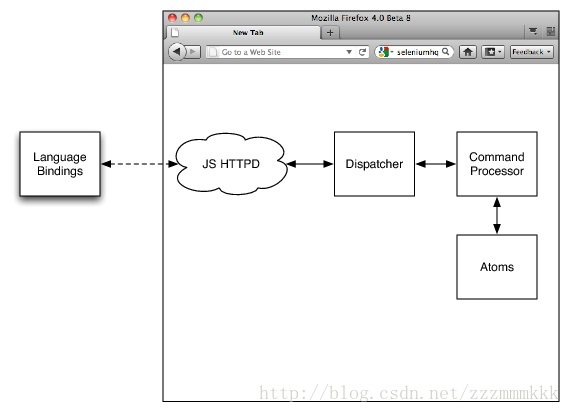
Firefox driver被实现成一个Firefox扩展,它的基本设计如上图所示。有些不同寻常的是,它有一个嵌入式HTTP服务器,虽然最初我们使用我们自己创建的,在XPCOM上写的HTTP服务器并不是我们的核心竞争力之一,所以机会出现时,我们使用基本的由Mozilla自己写的HTTPD取代了它,HTTPD收到请求马上传递给调度对象。
调度器接收请求并遍历一个已知支持的URL列表,尝试找到相匹配的请求,这种匹配完成了在客户端上的变量插值,一旦精确匹配到,包括使用的动作,JSON对象,就意味着在构造要执行的命令。我们的案例中看起来像:
{
‘name’: ‘getElementAttribute’,
‘sessionId’: { ‘value’: ‘XXX’ },
‘parameters’: {
‘id’: ‘some_opaque_key’,
‘name’: ‘rows’
}
然后将其作为一个JSON字符串传递到一个自定义的XPCOM组件中,我们叫它CommandProcessor。
var jsonResponseString = JSON.stringify(json);
var callback = function(jsonResponseString) {
var jsonResponse = JSON.parse(jsonResponseString);
if (jsonResponse.status != ErrorCode.SUCCESS) {
response.setStatus(Response.INTERNAL_ERROR);
}
response.setContentType(‘application/json’);
response.setBody(jsonResponseString);
response.commit();
};
// Dispatch the command.
Components.classes[‘@googlecode.com/webdriver/command-processor;1’].
getService(Components.interfaces.nsICommandProcessor).
execute(jsonString, callback);
这里有大量的代码,但是有两个关键点。首先,我们把上面的对象转换成JSON字符串,其次传递一个回调的执行方法来发送HTTP响应。
命令处理器的执行方法通过查找“name”来决定调用哪个方法,然后做什么。第一个参数是一个“响应”对象(这么叫是因为最初只是用于将响应发回给用户),它封装的不只是可能发送的值;还有一个方法,使要调度的响应返回给用户以及可以找出有关DOM的实现机制。第二个参数是上面参数对象的值(在这里是Id和name)。这个方案的优点是每个函数都有一个统一的接口,反映了在客户端上使用的结构,这意味着用来思考每一端的代码的心理模式是相似的。这是getAttribute的底层实现,在之前也看到过:
FirefoxDriver.prototype.getElementAttribute = function(respond, parameters) {
var element = Utils.getElementAt(parameters.id,
respond.session.getDocument());
var attributeName = parameters.name;
respond.value = webdriver.element.getAttribute(element, attributeName);
respond.send();
};
为了使元素引用一致,第一行是在缓存中通过不透明的ID查找被引用的元素。在Firefox driver中,那个ID是一个通用唯一识别码,cache是一个map。这个getElementAt方法还检查元素是否已知并且附加到DOM上,如果检查失败,ID则从缓存中移除并抛异常返回给用户。
第二行之前讨论过的是利用浏览器自动化原子,这时候编译为一个单个脚本并加载为扩展的一部分。最后一行调用了send方法,做了个简单的检查,确保在调用执行方法的回调前一次只发一个响应。该响应是以JSON字符串装到对象里的形式发回给用户(假设getAttribute返回7,意思是没有发现元素)。
{
‘value’: ‘7’,
‘status’: 0,
‘sessionId’: ‘XXX’
}
然后Java客户端检查状态的值,如果该值非零,就把数字状态码转换成正确类型的异常抛出来,使用“value”字段设置发送给用户的消息,如果状态为零“value”字段的值直接返回给用户。
大部分能行的通,但是有一位聪明的读者提出个问题:在调用执行方法之前为什么调度器把对象转换成一个字符串?
这样做的原因是Firefox driver还支持纯javascript编写的测试脚本。通常情况下,这是件非常难以实现的事情:测试都是在浏览器的Javascript安全沙盒中运行,因此可能不会做一系列对测试有用的事情,如在不同域之间切换或上传文件等。但是,Webdriver的Firefox扩展提供了一个解决办法,属性添加到文档元素上以证明它的存在。Webdriver的Javascript API使用它作为一项指标,它可以添加JSON序列化的命令对象作为文档元素的命令属性的值,触发一个自定义的webdriverCommand事件,然后在被通知响应已确定的相同元素上监听webdriverResponse事件。
这表明在一个装有Webdriver扩展的firefox版本里浏览网页是一个坏点子,因为它使其他人远程控制浏览器变得更容易。
在后台有一个DOM消息器,等待webdriverCommand读取序列化的JSON对象并调用命令处理器的执行方法。这次,回调是在文档元素上设置了响应属性,然后触发预期的webdriverResponse事件。
本文是译文,原文请参考:http://www.aosabook.org/en/selenium.html
IE Driver
IE 是一个很有意思的浏览器,它是由一些协同工作的COM接口构建成的,这一直延伸到JavaScript引擎,常见的Javascript变量实际参考了隐含的COM实例。Javascript窗口是一个IHTML窗口,文档是一个COM接口IHTML文档的实例。微软已经做了非常出色的工作通过增强浏览器来维护现有的行为。这意味着如果一个应用程序如果支持IE6的COM类,它仍可以支持IE9。
IEDriver随着时间推移体系结构也跟着演变,一个非常迫切的需求设计是为了避免安装程序,这是个不常用的需求,所以需要一些解释。首先,当一个开发人员下载个包,在很短暂的时间内,它使用 WebDriver很难通过5分钟的测试,更重要的是WebDriver用户不能在自己的机器上安装软件,这意味着当项目想在IE上测试时,大家不需要记得登陆到持续集成的服务器上运行一个安装文件,,最后, 有些语言并不需要运行安装包,常见的Java就是添加JAR文件路径到CLASSPATH中,并且我的经验告诉我需要安装包的那些类库并不太受欢迎。
所以,最后选择结果是不需要安装包。
在windows上编程使用的自然语言是运行于.NET上可能是C/#。 通过使用在每个版本的window中都有的IE COM自动化接口,IEDriver集成了IE。特别是,我们通过调用原生的MSHTML和ShDocVw的dll文件使用COM接口,从而形成IE的一部分。在C/# 4中,CLR/COM互操作性通过使用单独的主互操作程序集(PIAs)完成,PIA本质上是一个在CLR和COM上的一座桥梁。
遗憾的是,使用C/# 4将意味着使用一个很新的.NET RUNTIME版本,很多公司避免走在技术的前沿,更喜欢稳定性好的和问题已知的老版本。使用C/# 4我们会自动排除一定比例的用户群,使用PIA也有一些其他缺点。考虑到许可的限制,在于微软协商后,很明确的是,Selenium项目不会有权利发布PIA,无论是MSHTML或ShDocVw类库。即使被授权,每个安装的windows和IE都有一个类库的唯一组合,这意味着我们需要处理很多这样的事情,按需构建客户机的PIA也并不可行,因为他们需要一些可能在普通用户机器上并不存在的开发者工具。
所以,尽管C/#是一种很有吸引力的编程语言,但不能选它。至少在与IE通信时,我们需要使用一些原生的东西。很自然的下一个选择就是C++,这也是我们最后选择的语言。使用C++有一个优势就是我们不需要使用PIA,但是它意味着我们需要重新发布Visual Studio C++ 运行的 DLL,除非我们静态链接他们。因为为了能使用那个DLL我们需要运行一个安装程序,链接类库与IE进行通信。
如果不使用安装程序确实需要支付非常高的成本,但是,回想以前复杂的方案,为了让我们的用户更容易的使用是很值得投资的。结论就是我们对当前的工作重新评估,因为为了给用户带来好处,需要付出的是能给一个高级C++开源项目做贡献的人数看起来似乎比那些贡献于同样的C/#项目的人要少。
IE driver原始设计如下图:
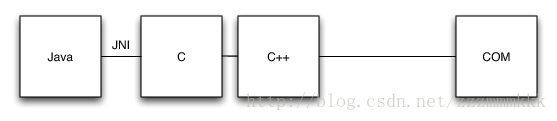
从堆栈底你可以看到我们使用IE的COM自动化接口,为了在概念层面上更容易的应付,我们包装了这些原始的接口使用了一组C++类,深刻反映了主要的WebDriver API。为了获得与C++通信的的JAVA类,我们使用了JNI,通过COM接口的C++ 抽象的JNI方法实现。
这种方法当JAVA是唯一的客户端语言时很适用,但是如果每种语言都需要改变底层类库的话,它就很痛苦且过于复杂。所以虽然JNI能起效,但是它不提供正确的抽象层。
什么是正确的抽象层呢?每种语言,我们想支持的每种语言都有一种直接调用C代码的机制,在C/#里,需要PInvoke的形式。在Ruby里是FFI,Python是ctypes,而在JAVA里,有一个很棒的库JNI(JAVA Native Architecture)。我们需要使用最常用标准来开发API,通过我们的对象模型,扁平化,使用一个简单的两三个字母前缀表示主接口方法,WD代表WebDriver,wde代表WebDriver Element。因此WebDriver.get变成了wdGet,WebElement.getText成了wdeGetText。每个方法返回一个整数的状态码,out参数用于表示允许函数返回值,我们不再使用像这样的方法签名:
int wdeGetAttribute(WebDriver/, WebElement/, const wchar_t/, StringWrapper//*)
为了调用代码,WebDriver, WebElement 以及StringWrapper是不确定的类型,我们说明了API中的差异,使得更清楚应该使用什么值作为参数,尽管可以简单的使用void。因为我们想正确处理国际化文本,你也可以看到我们使用宽字符文本。
在JAVA端,我们通过一个接口公开了这个方法库,然后我们使它看起来像普通的面向对象的接口,例如,Java定义的getAttribute方法看起来像:
public String getAttribute(String name) {
PointerByReference wrapper = new PointerByReference();
int result = lib.wdeGetAttribute(
parent.getDriverPointer(), element, new WString(name), wrapper);
errors.verifyErrorCode(result, “get attribute of”);
return wrapper.getValue() == null ? null : new StringWrapper(lib, wrapper).toString();
}
设计图如下:
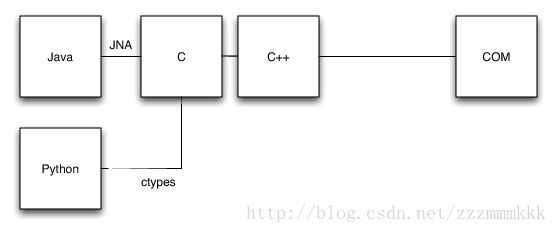
所有的测试都在本地机上运行,这样子不错,但是一旦我们在远程WebDriver上使用IE driver时,就会随机锁定,我们跟踪过这个问题是因为IE 对COM自动化接口的限制。它们这么设计是用在单线程单元模式,本质上讲,归结到一个要求就是,我们每次在同一线程中调用这个接口。在本地运行时,默认情况就是这样。然而,Java 应用程序服务器,使用多个线程处理预期负载,结果呢?我们没有办法确保所有情况下是在同一线程里访问IE driver。
对于这个问题的解决方案是将IE driver在单线程执行器里运行,在应用程序服务器里通过Futures序列化所有访问,一段时间内我们是这样设计的。但是,似乎在调用代码中如此复杂并不公平,很容易想象这样的情形,人们一不小心从多个线程中使用IE driver,我们决定降低driver本身的复杂性。在一个单独的线程中使用IE实例使用PostThreadMessage Win32 API 跨线程边界通信,因此,在写此文时,IE driver的设计看起来像下图:
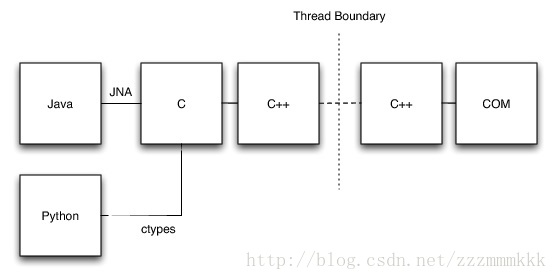
这不是我们会自愿选择的那种设计,但是它具有可工作性和避免麻烦的优点,我们用户可能会选择它。
这种设计的缺点是,它很难决定IE实例是否锁定它本身。当我们与DOM交互时如果一个对话框打开了,或者在线程边界的那一边发生了灾难性的失败,可能就出现了。因此我们发送每一个线程消息都会有一个timeout超时,我们设置为相对宽松的2分钟。从用户邮件反馈来看,这个假设大致如此,但并不正确,在IE driver更高版本里把超时时间做成了可配置的。
另一个缺点是内部调试可以深入问题,但需要快递完成(毕竟,你只有两分钟时间尽可能的跟踪代码),随后跨线程使用断点以及了解期望的代码路径。不用讲,在一个开源项目里,有很多有趣的问题需要解决,很少有食欲。这显著的降低了系统的“巴士因素”,作为项目的维护者,这让我很担心。
为了解决这个问题,越来越多的IE driver的内容移植到了相同的自动化原子如Firefox driver和Selenium Core。我们通过编译计划要使用的每个原子并准备将其作为C++头文件,每一个功能都公开成一个常量,在运行时,我们准备从这些常量中执行Javascript。这种方法意味着我们可以给IE driver开发测试一定比例的代码,而不需要C编译器,也不许更多人投入定位解决错误。最后,我们的目标只是保留原生代码中交互的API,并依赖进更多的原子。
我们正研究的另一个方法是重写IE driver来使用轻量级的HTTP 服务器,可以让我们把它当成远程WebDriver。如果发生这种情况,我们可以降低很多线程边界的复杂性,减少代码总量,让控制流易用性显著增强。
未完待续,敬请期待以后的文章:
本文是译文,原文请参考:http://www.aosabook.org/en/selenium.html