JDK中JUC包由浅入深原理——atomic包
条评论intel CPU原子操作
需有一个基本逻辑,CPU不支持的,上层不可能自己YY出来。沿着操作系统内核往应用层,通常都是利用底层的能力,构筑上层的大厦。
在intel中,指令lock+指令,可构成一个原子指令(即要么都执行,要么不执行)。上层代码,可基于此构建自己的原子操作。
依据可查阅intel开发手册Volume3 - 8.1到3。

从上可知,通常套路原子指令大概就有:
1 | LOCK; ADDL $0,0(%%esp) //栈底加0,什么也不做 |
1 | CMPXCHG; //自带LOCK |
JDK和hotspot源码
以java.util.concurrent.atomic.AtomicInteger为例
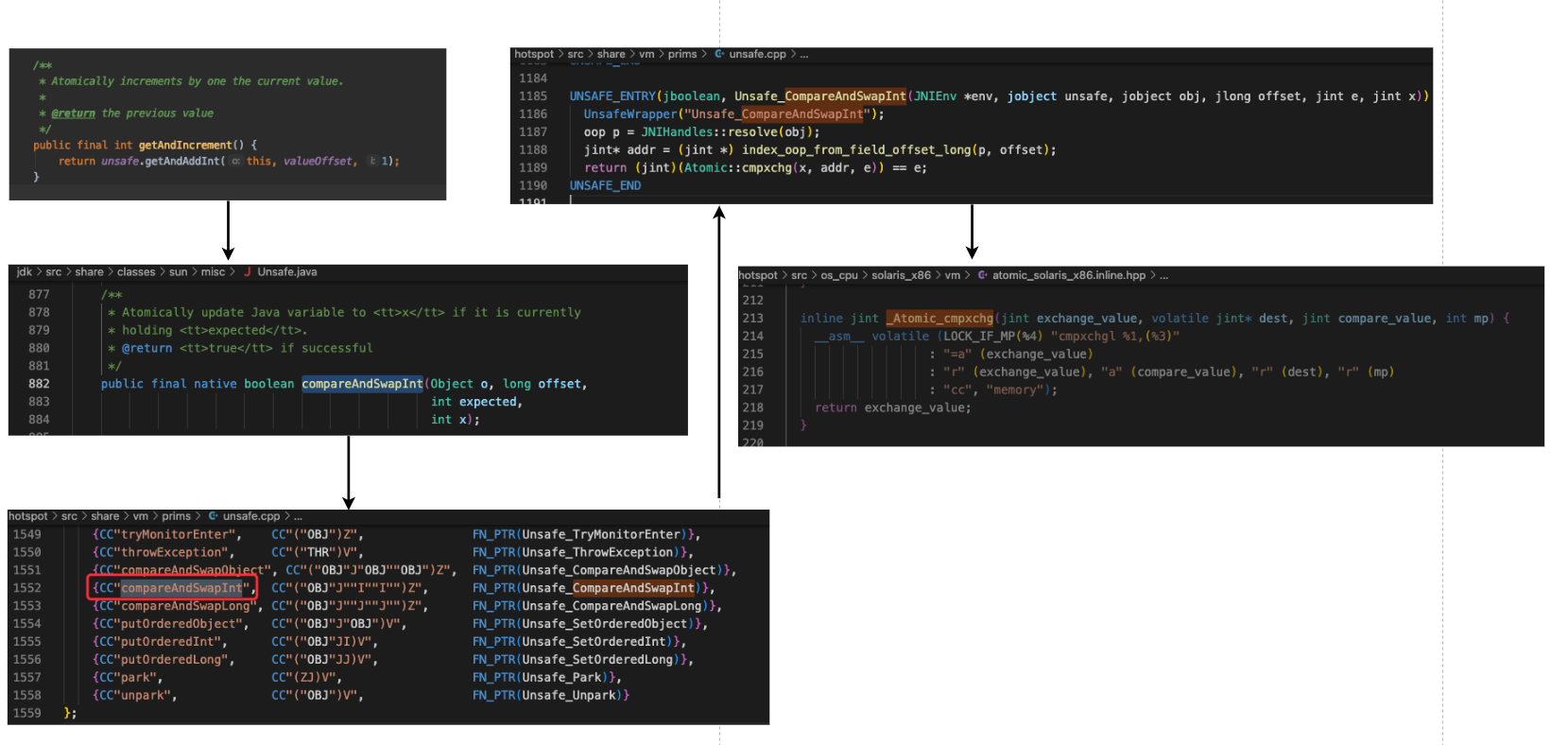
上图展示了从jdk到jdk源码,到hotspot源码,类AtomicInteger中的getAndIncrement方法的调用链路。到hotsopt层面就一句核心:
1 | #define LOCK_IF_MP(mp) "cmp $0, " #mp "; je 1f; lock; 1: " //定义宏,如果mp与0相等,则跳过lock指令,否则执行lock |
以上内联代码转义为正常汇编代码,大概如下:
1 | cmp $0, " #mp "; //mp = multi processor 多核 |
intel手册该指令解释如下:

所以,lock;cmpxchg提供了atuomic包下面的底层支持。
ABA问题
并发条件下通过cmpxchg方式操作,存在aba问题,即cpu对同一个值改动2次,从A改到B又改回A,其他cpu并不知道值变过,解决办法就是加版本号(Stamped)。在juc包中对应的类为:AtomicStampedReference。它的原理类似上面。
LOCK指令
lock指令为什么能保证指令的原子性呢?
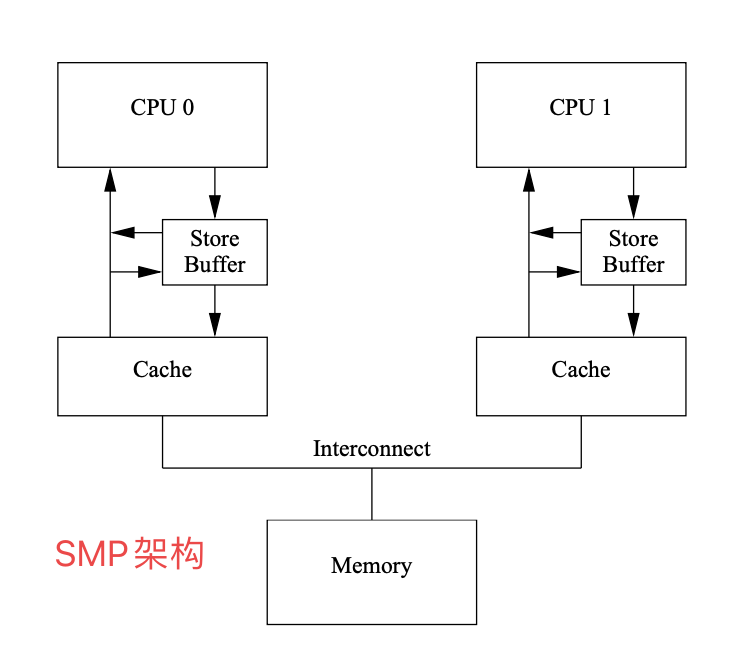
核心:在CPU内部中有个store buffer,可提高CPU执行效率。同时带来了多核情况下,同一个内存中的值,在不同CPU当中的可能是不同的(写回内存前,没有刷出store buffer)。lock指令锁住了数据总线的同时,主动刷出了store buffer,通过cache的连通性( Store Forwarding),其他CPU会获知自己拿的值过期,可更新到最新值。