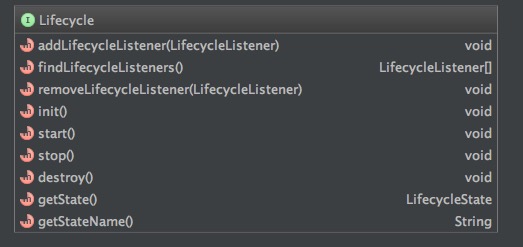
【计算机理论基础】计算机是如何做运算的
由低向上的学习计算机是一条比较漫长的道路。但是,得来的知识却是体系化的。而且越到上边,学习的理解的效率是越高的(暂且自我欺骗,毕竟还没达到那高度)
下面就最近研究和学习做一个复盘。以问题出发为脉络。
1、计算机是怎么做运算的?
关键字:二进制、逻辑门
2、在问题1的基础上又问:为什么是二进制?
3、CPU是如何工作?
1、计算机是怎么做运算的?
回答这个问题,要先弄懂人类在使用10进制做计算时的方法,不赘述。
10进制方法迁移到二进制。基本的加法、乘法(可转成进位的加法),减法转成加法实现,除法转成乘法实现(这个我还没深究)。
进制之间可以平滑的换算。
数和进制的抽象
(这是我独立思考得出的,未见有人说过,或者有但我不了解)。
位和进制大小、进位。是三个基本元素。
位是进位中的位,是进制数的承载单元。位只能承载(0到进制-1)的数。比如:10进制中,一个位可以放0-9的数字,到10的时候就需要进位。二进制,最大放1,到2就要进位。
进制大小:就是所谓的2、10、16。
进位:位中承载的数等于进制大小时,发生的高位+1行为。
所以,可以有5进制。甚至可以有100进制,当然如果能够找到这么多数字的象征,恐怕人类的大脑处理起来也是费尽的。
问题又来了,为什么人类有进制这种抽象,我觉得主要还是来源于认知的范围是有限的,而认知的对象是无限的。之所以说认知范围是有限的,主要是人的身体机能决定的,不能同时(并行)思考和处理多个问题。以有限的认知认识无限,只能将无限的进行分而治之。数字是对现实世界和数量有关的一种抽象。位,就是数字抽象的基本单元。对于人类来说,现实世界的物质是无限的,小到分子原子、大到宇宙万物。所以用进制数可以表示一个特定的数量的概念。
如果存在一个主体(比如上帝),ta使用的是无限进制,宇宙万物都囊括在其中,它不用进位。每个事物都有是唯一的,那么人类的进制就已经没有了意义,ta能使用无限进制的前提是掌握了无限事物的信息,超人类思维的存在。这就是无限这个抽象的力量。
什么是运算
传送门
人类为什么要做运算呢?因为人类的认知是有限的啊,为了得到暂时无法获得的信息,基于已有的信息进行信息的变化和组合,就生成了运算。所以,如果人类可以直接获得任何信息,比如看到一个平面物体,便知道它的面积和体积,那基于几何学的长宽高、积分之类的运算就不再具有它的价值,但这目前还只是一种思维游戏,人类还是渺小的。
这里举个例子:
国王统治了100个小城邦,他欲了解各城邦的粮食产量这个信息,以备决策。最简单的方式就是,统计各城邦的产量,然后全部相加。
如果没有数字和运算,他要得到信息,需要把100个城邦的粮食搬到一起,进行称重了。
插个题外话,统计出来的数字只是一种近似值,为什么呢?因为在实操的过程中,城邦是可以谎报数量的,可以报大或报小,加起来的数已经不是国王心中想要的那个数了,但是这也没有办法,先解决有和无的问题,只要偏差不大的离谱,是可以容忍和妥协的。妥协这词在计算机的实现中也是常见的。
物理学中的很多问题都是靠运算得出的,比如光速是怎么得来的(人类一开始测量得到的光速也只是近似值)?天体物理学又靠什么说宇宙在膨胀?
所以,再不要把运算限定在10进制了,它只是众多进制中人类习以为常的一种而已。
结合进制和运算: